python笔记-错误和测试错误处理try12345678910111213try: print('try...') r = 10 / int('2') print('result:', r)except ValueError as e: print('ValueError:', e)except ZeroDivision 2024-07-28 Coder #python
面经Linux LinuxA磁盘的文件全部迁移到B磁盘 dd命令 如何创建lvm卷? fdisk分区–>pvcreate–>vgcreate–>lvcreate–>格式化–>挂载 100亿小文件删除,对比怎么删除比较高效? find + xargs实现分批删除 find命令可以在找到文件的同时逐个处理,不需要将整个文件列表读入内存. find命令的算法可以更快地便 2024-06-20 面经 #Interview
AWS-SAP-MustKnow服务类型总结计算(Compute):Amazon EC2(Elastic Compute Cloud) spot: 使用aws上未被使用的计算资源,随时可能被终止,适用于批处理,科学计算等,价格按供需变化 预留: 预定计算资源(一般是1年或3年),折扣比按需大 按需: 按小时或秒收费 节省计划: 在一定时间内(一般是一年或三年)使用一定量的计算资源,换取比按需更低的价格 集群放置组: 在单可用区 2024-03-20 Cloud #AWS
python-面向对象高级特性动态绑定属性和方法python是一种动态语言,而动态语言的类的属性和方法可以动态绑定 123456789101112131415161718# 比如有这么一个类class Student(object): pass# 动态绑定属性s = Student()s.name = 'Peter'print(s.name)# 动态绑定方法def set_age(self, age) 2024-02-24 Coder #python
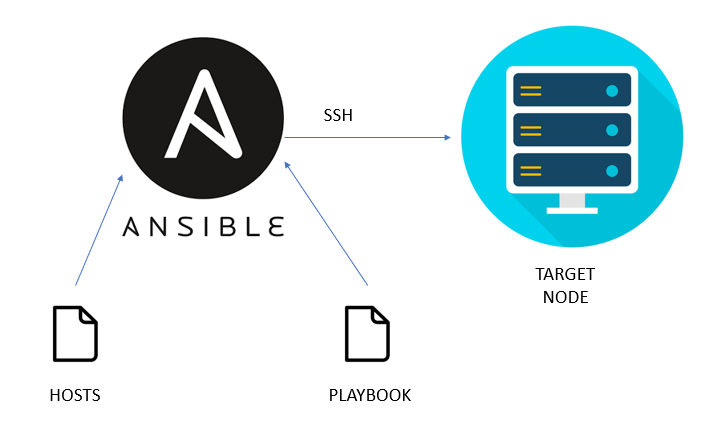
ansible-必知必会中文文档 原理 Ansible的名字来自小说<安德的游戏>是一个跨越时空的通讯工具 Ansible本质上只是一个框架,用python开发,实际通过它的库实现功能,其中有三个关键库: Paramiko: Python对ssh的实现 PyYaml: 解析和生成yaml jinjia2: 用于模板的生成,在使用 template 模块自动生成文件时特别有用 特性: 基于python 2024-02-22 技术笔记 #ansible
k8s-理论重要组件控制平面: apiserver: 集群的API入口,所有内部通信都通过apiserver,集群控制面前端. etcd: 分布式键值存储,存储集群配置,状态等数据,是整个集群的最终数据源. scheduler: 负责调度决策,分配pod到相应的node上. controller manager: 负责管理控制器(deployment,daemonset,stateful等等). 工作平面: 2024-02-20 技术笔记 #k8s
k8s-监控与日志外部Prometheus 关于prometheus监控k8s集群的方案可以看看: prometheus-book 这篇文章 以上两篇参考都是将prometheus部署在集群内为前提,本文是将Prometheus部署在集群外部,主要参考了: 这篇博客 和ChatGPT-4 kube-state-metrics 用于生成关于 Kubernetes 对象状态的广泛指标。它从 Kubernete 2024-02-16 工作笔记 #prometheus #k8s #CRD
k8s-运维K8S运维记录以下管理k8s集群会用到或者我觉得可能会用到的东西. 证书管理CA: 根证书颁发机构 通过kubeadm管理,目录路径: /etc/kubernetes/pki 1234567891011121314151617181920212223├── apiserver.crt├── apiserver-etcd-client.crt├── apiserver-etcd-client.key 2024-02-15 技术笔记 #k8s
k8s-部署Background 随着k8s的更新迭代以及centos 7的退出,所以总结这一篇新文章,记录k8s集群的在rocky9上的部署和使用. 除了kubeadm管理的组件: api-server secheduler controller-manager etcd kube-proxy 还包括: Calico(CNI) Helm metrics-server ingress-nginx 这些 2024-02-15 技术笔记 #k8s
kakfa-必知必会概述分布式流处理平台,它提供了一种高吞吐量、可持久化的消息传递系统.kafka本身没有管理配置和注册功能,所以kafka集群强依赖zookeeper,用于存储meta数据以及选举. Kafka 的设计目标是提供高吞吐量和分布式处理能力,而不是保证消息的顺序,很多时候消息的顺序问题要在消费者上进行处理. kafka增加和减少服务器都会在Zookeeper节点上触发相应2的事件kafka系统会捕获这 2024-02-03 工作笔记 #kafka