k8s-理论
重要组件
控制平面:
apiserver: 集群的API入口,所有内部通信都通过apiserver,集群控制面前端.
etcd: 分布式键值存储,存储集群配置,状态等数据,是整个集群的最终数据源.
scheduler: 负责调度决策,分配pod到相应的node上.
controller manager: 负责管理控制器(deployment,daemonset,stateful等等).
工作平面:
kubelet: 在每个节点上,负责管理节点上pod的生命周期
kube-proxy: 节点网络代理,ipvs/iptables规则(service)就是它来维护.
core-dns: 集群内的DNS.
第三方但必须:
CNI: 如calico,负责pod之间的通讯,以及集群内的网络策略(NetworkPolicy)实现.
重要资源
k8s里面一切皆资源(resources).
service: 本质上是iptables/ipvs转发规则,负责对外暴露服务.
Pod: k8s基本部署单元,包括网络,存储以及如何运行怎么运行容器的规定.
namespace: k8s集群的逻辑隔离分组.
volume: 卷,提供持久化存储能力和共享存储机制.
configmap: 存储配置文件.
secret: 存储机密数据(默认使用base64加密).
控制器: 控制pod的生命周期,不同类型有不同的定义.
deployment: pod的副本及更新管理.
replicaSet: 保证任何时候都有指定数量的pod副本.
StatefulSet: 为有状态应用设计,提供稳定的,唯一的网络标识符,以及稳定的持久化存储和部署顺序保证.
DaemonSet: 确保所有(或特定)节点上都运行一个pod副本.
job和CronJob: 用于处理一次性任务和定时任务.
PV和PVC: PV对应实际的物理存储资源,PVC是用户对存储资源的请求.集群会根据PVC自动创建PV.
ingress: 管理外部对集群内部服务的访问,提供http和https路由规则.(有ingress-controller提供).
ResourceQuota: 限制namespace层面的资源.
1 | |
LimitRange: 限制pod或container层面上的资源大小.
1 | |
RBAC
是k8s的访问控制机制,有以下四种资源组成:
serviceaccount: sa,可以理解为就是一个用户名,命名空间级资源.role: 角色,权限赋予给role, 命名空间级资源clusterrole: 与role一样,但是是集群级的资源rolebinding/clusterrolebinding: 负责将sa和role/clusterrole关联起来
Addition
init-pod
在pod中定义一个先于其他容器启动的小容器,用于在主容器启动前完成一些必要的初始化配置.
1 | |
常见场景:
- 启动时进行数据库或缓存的初始化
- 下载配置信息
- 检查依赖关系
- 创建数据卷
- 网络初始化
Pause
是一个隐蔽但重要的容器,1.19前称为kube-pause,1.19后被合并进kubelet,并改名为PodSandbox.
负责保持并管理容器的命名空间(这里指的LXC的内核的命名空间),它负责初始化并保持命名空间(比如网络和PID),这样子其他容器就可以在相同的pod中共享这些命名空间.
命名空间锚点:Pause容器创建了网络和PID两个重要的命名空间。这些命名空间为Pod内所有的容器提供了共享的环境和上下文。其它容器在初始化时会加入到Pause容器创建的命名空间中,并在这些共享的空间内运行。
Pod级别的生命周期管理:由于Pause容器是Pod启动时最先创建的容器,其生命周期与Pod一致。即使Pod内的业务容器被重启或崩溃后重启,Pause容器仍然在运行,这样保证了Pod的网络和PID命名空间在容器重启过程中是持久且稳定的。
资源共享:Pause容器为Pod内的其他容器挂载点提供共享的资源,比如卷挂载。这意味着即使业务容器出现重启,共享资源仍然可用,从而保证了容器间资源的持续连贯性。
处理僵尸进程:在Linux中,一个僵尸进程是已经完成但其父进程尚未对其进行回收的进程。Pause容器作为Pod内所有容器的共同父进程,有助于回收这些僵尸进程,从而避免资源泄漏。
防止孤立:如果没有Pause容器,且Pod内的所有业务容器都停止运行了,那么Pod的网络命名空间和PID命名空间可能会失去,这将导致任何重启的容器进入一个全新的环境。Pause容器的存在,使得Pod在其生命周期内始终保持一个稳定的运行环境。
安全
Secret的安全性
Secret是用来存储敏感数据的资源,本质上一种特殊的卷,但是默认情况下,secret只是将数据做了base64加密,假如数据被截获,敏感数据依旧可以轻松被获取.因此针对secret有一些额外的安全补充手段:
- 通过
RBAC和网络策略对secret进行访问控制 定期轮换secret- secret可以存放在
第三方密钥管理工具,比如AWS 的secret manager等,如果存放在etcd,可以对etcd配置加密(支持多种加密算法). - secret之间的传输使用
mTLS. 禁止硬编码,包括在日志打印中显示也要避免.
网络通讯
容器间通讯
同一个pod内多个容器共享网络命名空间,通过L0环回口通讯
相同节点pods间通讯
不同节点pods间通讯
k8s规定所有pod都要运行在同一个扁平的没有nat转换的网络中,物理上pod可以运行在不同的节点上,但是看起来他们就像运行同一个局域网中.实现这个要求的就是CNI,当pod创建或销毁时,CNI就负责pod的网络配置,比如分配ip,配置路由等.
不同的CNI的实现方式不一样,以主流的fannel和calico为例:
Flannel
Flannel主要支持两种后端:
VxLan(默认)
类似VPN,在两个pod之间建立虚拟的网络隧道实现通讯.是一种在
3层网络上通过封装原始数据包来创建一个虚拟的2层网络来实现的点对点通讯.工作方式:VXLAN 使用 UDP 数据包来封装和转发原始的以太网帧。每个主机以 VTEP(VXLAN Tunnel Endpoint)的身份运行,负责封装和解封装从 Pods 发出或发送到 Pods 的数据包。
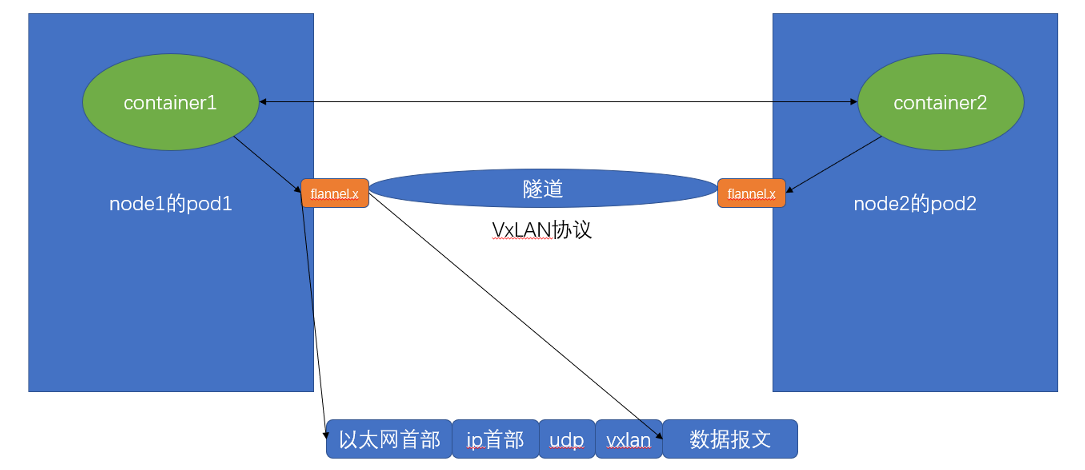
缺点: 隧道通讯,多层封装,开销大
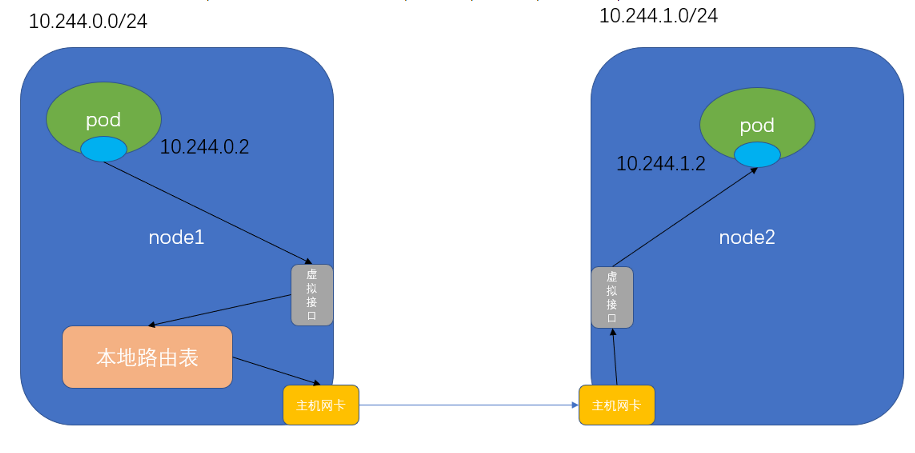
Host-GW
Flannel在初始化时会被分配一个大的IP段,然后会自动将这个大IP段分割成多个小的子网块,这些子网会分配给各个节点.每个节点上维护一个
静态路由表.每个节点的pod都在独自的网段中,通过静态路由到达目标节点的网段,从而到达目标pod.
Calico
默认与Flannel的host-GW类似,不过Calico使用的是动态路由协议(BGP)来维护和更新路由表.
另外Calico也支持VxLan模式的封装.
Flannel VS Calico
| Calico | Flannel | |
|---|---|---|
| 实现方式 | 1. VxLan(默认) 2. Host-GW静态路由 | 1. 动态路由协议 2. 支持VxLan |
| 性能 | 默认使用隧道,性能差 | 默认直接使用路由,性能等同主机网络 |
| 网络策略 | 不支持 | 支持 |
| 配置管理 | 简单 | 复杂,粒度细 |
Service
ClusterIP
Service本质上是kube-proxy管理的一系列iptables/ipvs规则,其Cluster-IP(本质上是一个虚拟IP)实际上是kube-controller-manager负责管理提供.给集群内部的其他组件使用访问后端的一组pod.
当一个pod试图通信到一个service的Cluster-IP,kube-proxy会介入数据流,从service绑定的endpoint中选择合适的后端Pod进行流量转发.因为kube-proxy使用iptables/ipvs规则实现流量转发,不涉及用户空间,所以性能优秀.
core-dns也会给每个svc绑定一个域名,映射对应的clusterIP
Headless
当使用Headless类型的service时,service只会绑定一个域名,而不会分配IP.
pod访问其域名,core-DNS返回的是一个所有后端Pod IP的列表
客户端需要使用返回的IP列表选择一个或多个来通信,也可以自行实现负载均衡去访问.
通常与statefulset一同使用,此时每个statefulset的pod都会有一个独立的网络标识和持久化存储.