k8s-监控与日志
外部Prometheus
关于prometheus监控k8s集群的方案可以看看:
以上两篇参考都是将prometheus部署在
集群内为前提,本文是将Prometheus部署在集群外部,主要参考了:
- 这篇博客
- 和ChatGPT-4
kube-state-metrics
用于生成关于 Kubernetes 对象状态的广泛指标。它从 Kubernetes API 获取元数据,然后转化成Prometheus指标格式以供Prometheus等监控系统使用。它生成的是”静态”数据,例如一个Deployment有多少副本正在运行,一个Service有多少个Endpoints,等等。跟
metrics-server是两个不同的东西,作用场景野不一样.
- kube-state-metrics 不能提供HPA和VPA所需的实时资源使用数据。
- metrics-server 不像
kube-state-metrics那样提供关于Kubernetes对象状态的丰富指标。
部署
1 | |
默认kube-state-metrics使用本地存储(应该都是些监控数据,部署prometheus获取后会存在prometheus中,所以应该不重要)且副本数为1,生产环境中部署要注意修改.
prometheus和grafana配置
prometheus配置
1 | |
grafana使用dashboard: kube-state-metrics-v2
接下来就是grafana的数据源,每个图表的promql等微调了(全是图形界面).
kube-state-metrics的metrics非常丰富,上面的dashboard只是用到一小部分,实际使用要根据具体环境自己创建dashboard.
原生metrics
k8s原生组件自带metrics API,下面以API-server为例子,演示如何通过TLS联通外部的Prometheus:
要使外部的Prometheus可以安全访问首先要给它创建SA,绑定token并授权
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus-monitor-sa
namespace: prometheus # SA是namespace级资源,为了好区分,我给它额外创建了个promethes的namespace
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus-monitor-cr
rules:
- apiGroups:
- ""
resources:
- nodes
- nodes/proxy
- pods/proxy
- nodes/metrics
- services
- endpoints
- pods
- ingresses
- configmaps
verbs:
- get
- list
- watch
- apiGroups:
- "extensions"
- "networking.k8s.io"
resources:
- ingresses/status
- ingresses
verbs:
- get
- list
- watch
- nonResourceURLs:
- "/metrics"
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus-monitor-crb
subjects:
- kind: ServiceAccount
name: prometheus-monitor-sa
namespace: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus-monitor-cr
---
apiVersion: v1
kind: Secret
metadata:
name: prometheus-monitor-tk
namespace: prometheus # secret是namespace级资源,为了好区分,我给它额外创建了个promethes的namespace
annotations:
kubernetes.io/service-account.name: prometheus-monitor-sa
type: kubernetes.io/service-account-token生成token文件并传到prometheus服务器
1
2kubectl get secrets -n prometheus prometheus-monitor-tk -o jsonpath="{.data.token}" | base64 --decode > prometheus.token
# 然后scp传过去除了token文件,ca证书也要传过去:
/etc/kubernetes/pki/ca.crt配置Prometheus
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24scrape_configs:
- job_name: kubernetes-apiservers
# k8s自动发现
kubernetes_sd_configs:
- role: endpoints
api_server: https://<api-server_ip>:<api-server_port>
bearer_token_file: /root/prometheus/pki/prometheus.token
tls_config:
ca_file: /root/prometheus/pki/ca.crt
# 由于使用的是自签证书所以要skip_verify
insecure_skip_verify: true
relabel_configs:
# 根据regex正则匹配下面的source_labels,匹配上的就keep(保留下来写入Prometheus)
- action: keep
regex: .+;kubernetes;https
# 使用k8s自动发现获取的metrics,Prometheus会给它添加上一些labels,这里是根据这些labels做了些过滤
source_labels:
- __meta_kubernetes_namespace
- __meta_kubernetes_service_name
- __meta_kubernetes_endpoint_port_name
scheme: https
bearer_token_file: /root/prometheus/pki/prometheus.token
tls_config:
insecure_skip_verify: true
常用metrics
ChatGPT-4生成:
kube-apiserver:
- apiserver_request_total: API 服务器处理的请求数量。
- apiserver_request_duration_seconds: 请求的处理时间。
- apiserver_client_certificate_expiration_seconds: 客户端证书的过期时间大小。
etcd:
- etcd_request_duration_seconds: ETCD 存储请求的延迟时间。
- etcd_disk_wal_fsync_duration_seconds: 写入和同步预写日志文件操作所花费的时间。
- etcd_network_client_grpc_received_bytes_total: 通过 gRPC 接收的字节总数。
kube-controller-manager:
- workqueue_depth: 工作队列的深度。
- workqueue_adds_total: 添加到工作队列的总项目数。
- controller_runtime_reconcile_time_seconds: 控制器中 reconcile 方法的耗时。
kube-scheduler:
- scheduler_e2e_scheduling_duration_seconds: 调度程序从开始调度到完成调度的时间。
- scheduler_schedule_attempts_total: 调度尝试的总数,按结果进行分类。
- scheduler_pod_preemption_victims: 每次抢占事件中的受害者 pod 数量。
内部Prometheus
使用deployment部署
1 | |
Prometheus-Operator
CRD
在了解Operator之前,先来了解一下CRD(CustomResourceDefinition).
想象k8s是一个可扩展的积木系统,那么它原有的积木类型(内置资源类型)有:
2
3
4
5- Pod
- Service
- Deployment
- ConfigMap
...就是客制化定义一个新的资源类型,比如定义一个prometheus资源类型
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27# 通过 CRD 定义一个新的"积木类型" - Prometheus
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: prometheuses.monitoring.coreos.com
spec:
# 定义这个"新积木"的规格
group: monitoring.coreos.com
names:
kind: Prometheus # 新资源类型的名字
plural: prometheuses
scope: Namespaced
versions:
- name: v1
served: true
storage: true
schema:
# 定义这个"新积木"可以有哪些属性
openAPIV3Schema:
properties:
spec:
type: object
properties:
replicas:
type: integer
version:
type: stringCRD从创建到可用大概过程
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16步骤 1: 注册新的"积木类型"
┌────────────────┐
│ 提交 CRD 定义 │
└────────────────┘
↓
步骤 2: API Server 处理 (等待Kubernetes完全理解和接受这个新类型)
┌─────────────────────┐
│ - 验证定义 │
│ - 创建新的 API 端点 │
│ - 设置数据存储 │
└─────────────────────┘
↓
步骤 3: CRD 变为可用状态
┌────────────────────┐
│ 现在可以创建新类型 │
└────────────────────┘
CR
可以这么理解CRD是类,CR则是类的具体实例.
日志收集方案
技术栈选择
elasticsearch+logstash+kibana: 是最著名的日志收集方案,但是elasticsearch和kibana在新版本中都推出企业lic,不能免费使用它的全功能,所以要么使用旧版本,要么只使用它的部分功能,要么给钱.至于logstash,则有不少更轻量或更新的替代产品,比如loki,Fluentd等,都是开源的.这方面的选择就比较多.
Prometheus+grafana+loki: 比较适合中小型集群,这个技术栈的特点是全开源且轻量,还能直接集成监控系统.
opensearch+logstash: opensearch是AWS发起的,旨在完全兼容elasticsearch功能的开源工具,它取自elasticsearch+kibana的分支,诞生在elasticsearch+kibana不再完全开源免费之后.自带一个opensearch dashboard可以替代kibana功能.性能上还比不上elasticsearch.但是如果你希望免费部署日志收集系统,可以接受一部分的性能下降,这是个很不错的选择,AWS云也有使用opensearch的公共服务.
日志代理有很多选择: logstash/loki/Fluentd/Filebeat/…
日志收集等级
k8s支持三种不同等级的日志收集方式
sidecar: 在每个pod之内额外部署一个log agent的容器作为sidecar运行,收集日志数据,将日志发送到es/opensearch等日志存储系统.
节点级: 在每个节点上部署一个日志代理(Fluentd/Filebeat等),通常以daemonset的方式部署,收集的日志信息发送到集群外部的日志存储系统.
集群级: 就是把日志收集系统全部部署在集群内部,以获取最及时的日志数据.(比如你的集群部署在海外,如果把日志存储分析系统部署在国内,数据传输就会消耗一定时间).
三种级别的日志收集方式需要根据实际,选择使用,或者组合使用.
EFK
用Fluentd替代了Logstage.
Fluentd的主要特点有:
- 插件化架构,拥有丰富的插件生态系统,通过不同插件实现收集,过滤,缓冲和输出的不同功能
- 使用内存和文件基础的缓冲区机制,保护数据免受网络问题和宕机影响
- CNCF云原生项目
Fluentd的配置文件语法:
- fluentd的配置使用自己的标记语言编写,借鉴了XML的某些视觉元素,但不是XML.
- 使用
来表示配置开始 表示配置结束- 配置文件以
.conf为后缀,其内容包括:
- 指令:
, , 等 - 参数: 缩进的键值对
- 注释:
#
<source>: 指定日志数据来自何处
<match>和<filter>指定如何处理这些数据
Fluentd VS Logstage:
- Fluentd更轻量,默认配置配置下使用更少的内存资源
- Logstash提供更多的过滤器和插件,可以处理更复杂的数据逻辑
- Fluentd更容易上手
部署ES+Kibana
1 | |
1 | |
1 | |
部署Fluented
首先配置Fluented的配置文件,在EFK中这一步最为复杂,需要定义如何获取日志,如何处理日志,以及输出到哪里.
以下示例分三个配置文件,收集k8s集群内容器的日志文件:
system.conf
配置Fluentd的系统级参数
1
2
3<system>
root_dir /tmp/fluentd-buffers/ # fluentd使用的根目录,这是fluentd运行时临时文件的总目录
</system>containers.input.conf
以下配置文件定义了一些列规则,用于从k8s容器中收集,处理和过滤日志,主要操作有:
**日志收集:**使用tail插件监控特定路径下的日志文件
**异常检测和处理:**使用
detect_exceptions插件来识别和处理多行异常信息**日志连接与过滤:**使用
concat插件将多行日志合并成单个事件,使用grep插件根据标签过滤日志**元数据添加:**使用k8s元数据插件来添加有关k8s环境的信息
**日志清理:**移除日志中不必要的字段
**日志解析改善:**使用
parser插件进一步解析日志记录中的json字段,如果无法解析则保留原数据1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21<source> # 定义数据输入开始的标签
@id fluentd-containers.log # "@id"用于定义这个<source>配置的唯一标识符,相当于给这段<source>命名,方便日后管理和调试
@type tail # "@type"用于指定使用的插件,这里使用"tail"插件用于追踪日志文件的增长,并持续读取新增内容
path /var/log/containers/*.log # "path"使用路径模式指向一个日志文件,意味着fluentd会监听该路径下所有的.log文件,并读取其内容
pos_file /var/log/es-containers.log.pos # "pos_file"用于指定一个文件,该文件用来记录fluentd已经读取日志数据到哪个点,重启后也能从上次停止的位置开始读取
tag raw.kubernetes.* # "tag"用于给<source>输入的日志打标签,所有以这个<source>为源输入的日志都会以"raw.kubernetes."开头
read_from_head true # 首次读取日志文件时,是否从头开始读取数据
<parse> # <parse>配置块定义如何解析读取的数据,即数据的格式化方式
@type multi_format # 使用"multi_format"解析器插件,支持多格式解析
# 下面两个"<pattern>"指定两种不同的日志格式和对应的解析方法
<pattern> # 第一个模式指定使用json解释器
format json
time_key time # 指定json中哪个字段表示日志时间
time_format %Y-%m-%dT%H:%M:%S.%NZ # 定义这个时间字段的格式
</pattern>
<pattern> # 第二个模式使用正则表达式解析不是json的日志行
format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/ # 使用命名捕获提取time和stream(标准输出和标准错误),以及日志消息log本身
time_format %Y-%m-%dT%H:%M:%S.%N%:z # 同样定义时间字段的格式
</pattern>
</parse>
</source>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20# 在日志输出中检测异常,并将其作为一条日志转发
# https://github.com/GoogleCloudPlatform/fluent-plugin-detect-exceptions
<match raw.kubernetes.**> # <match>块匹配tag为raw.kubernetes.**开头的日志信息
@id raw.kubernetes
@type detect_exceptions # 使用detect-exceptions插件处理异常栈信息,它可以自动识别多行的异常堆栈跟踪,并将其作为单个日志事件进行聚合
remove_tag_prefix raw # remove_tag_prefix删除指定前缀(raw)
message log # message参数定义存储日志消息的字段名称,这里是(log)
stream stream # stream参数定义将会存储"stdout"或"sederr"这样的流字段(stream)
multiline_flush_interval 5 # 设置检测到异常后,在强制刷新前等待的最大秒数.如果在5秒内没有接收到新的日志行,插件会发送当前缓冲的日志事件
max_bytes 500000 # 限制单个异常事件可包含的最大字节数
max_lines 1000 # 控制单个异常事件可包含的最大行数
</match>
<filter **> # 匹配所有日志
@id filter_concat
@type concat # 指定concat过滤器插件,将日志事件中分散的多行信息连接为一个单独的日志事件
key message # key指定要处理并连接为多行信息的字段名称(message)
multiline_end_regexp /\n$/ # 指定一个正则,用来确定何时结束一个消息,并且可以将分散的行连接起来.这里指定"\n$"结尾的换行符.这里意味着每当一行以换行符结束,就为认为是一个消息的结束
separator "" # separator定义多行消息连接时使用的分隔符
</filter>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23<filter kubernetes.**> # 过滤器匹配所有kubernetes.**开头的标签
@id filter_kubernetes_metadata
@type kubernetes_metadata # 这个插件可以从k8s API中补充和丰富日志记录的元数据
</filter>
# 修复 ES 中的 JSON 字段
# 插件地址:https://github.com/repeatedly/fluent-plugin-multi-format-parser
<filter kubernetes.**>
@id filter_parser
@type parser # 指定parser过滤器类型,用于解析日志中的指定字段
key_name log # 指定过滤器要解析的字段名称(log)
reserve_data true # 是否在解析后保留日志记录中的原始数据
remove_key_name_field true # log字段解析成功后是否从记录中移除
<parse>
@type multi_format
<pattern> # 定义了两种模式
format json # 第一种是json,它会尝试把日志按照json格式解析
</pattern>
<pattern>
format none # 如果不匹配,则不解释
</pattern>
</parse>
</filter>1
2
3
4
5
6
7
8
9
10
11
12
13
14# 删除一些多余的属性
<filter kubernetes.**>
@type record_transformer # 这个过滤器插件可以添加,删除或重命名日志记录中的字段
remove_keys $.docker.container_id,$.kubernetes.container_image_id,$.kubernetes.pod_id,$.kubernetes.namespace_id,$.kubernetes.master_url,$.kubernetes.labels.pod-template-hash # 要从日志中删除多余的属性,每个字段前的"$"指示查询的是记录本身的根
</filter>
# 只保留具有logging=true标签的Pod日志
<filter kubernetes.**>
@id filter_log
@type grep # grep插件用来包含或排除于特定模式匹配的日志记录
<regexp>
key $.kubernetes.labels.logging # 匹配日志中的哪个字段
pattern ^true$ # 正则匹配"true",只有当$.kubernetes.labels.logging 字段值完全等于 "true" 时,该日志记录才会被通过.
</regexp>
</filter>forward.input.conf
定义fluentd内部如何接收日志数据.这里定义fluentd实例将会监听一个端口等待其他fluentd代理或系统发送日志事件到这个地址.
在分布式日志收集系统中,forward插件可以使多个Fluentd实例相互传输日志数据.
1
2
3
4<source>
@id forward
@type forward
</source>@type forward,forward类型的source是用于接受其他fluentd代理发送过来的事件流.这种类型的输入插件会监听特定的端口,等待外部fluentd实例将日志事件直接发送到本实例.如果没有进一步配置(端口指定,安全设置,认证等),这个插件会监听默认端口(24224).output.conf
定义输出插件,将匹配到的日志输出到es服务器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24<match **> # 匹配所有
@id elasticsearch
@type elasticsearch # 使用es输出插件,将数据输出到es服务器
@log_level info # 定义Fluentd 插件自身输出日志的级别,于业务日志无关
include_tag_key true # 发送日志的时候是否包括时间标签的键
host elasticsearch # es集群主机名,这里直接使用es的headless svc名即可,因为是同一个namespace
port 9200 # es服务端口
logstash_format true # 启用logstash兼容模式, Fluentd 会生成 Logstash 索引名称格式有日期的时间戳的索引名
logstash_prefix k8s # 设置 index 前缀为 k8s, 索引名字将为"k8s-<日期>"
request_timeout 30s # 对es的请求超时
<buffer> # buffer块定义如何缓冲数据以及何时冲洗(flush)到es
@type file # 指定缓冲类型为文件, 意味着缓冲数据写入文件系统
path /var/log/fluentd-buffers/kubernetes.system.buffer # 指定缓冲文件(传冲插件使用的目录)
flush_mode interval # 设置冲洗模式为基于时间间隔冲洗
retry_type exponential_backoff # 重试类型为"指数避让"(重试等待时间逐步增长,避免对es服务造成过大压力)
flush_thread_count 2 # 冲洗操作线程数
flush_interval 5s # 冲洗的时间间隔
retry_forever # 无限重试
retry_max_interval 30 # 最长重试间隔
chunk_limit_size 2M # 缓冲区块大小限制
queue_limit_length 8 # 缓冲区队列长度
overflow_action block # 当缓冲区满了,进一步的数据处理将被"阻塞",直到缓冲区有空间可用
</buffer>
</match>将上面的配置作为configmap创建: 参考
使用daemon-set部署fluentd:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd-es
namespace: efk
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups:
- ""
resources:
- "namespaces"
- "pods"
verbs:
- "get"
- "watch"
- "list"
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
subjects:
- kind: ServiceAccount
name: fluentd-es
namespace: efk
apiGroup: ""
roleRef:
kind: ClusterRole
name: fluentd-es
apiGroup: ""
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-es
namespace: efk
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
selector:
matchLabels:
k8s-app: fluentd-es
template:
metadata:
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
spec:
serviceAccountName: fluentd-es
containers:
- name: fluentd-es
image: quay.io/fluentd_elasticsearch/fluentd:v3.4.0
imagePullPolicy: "IfNotPresent"
env:
- name: FLUENTD_ARGS
value: --no-supervisor -q
resources:
limits:
memory: 500Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /data/log/containers
readOnly: true
- name: config-volume
mountPath: /etc/fluent/config.d
tolerations:
- operator: Exists
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/log/containers
- name: config-volume
configMap:
name: fluentd-config
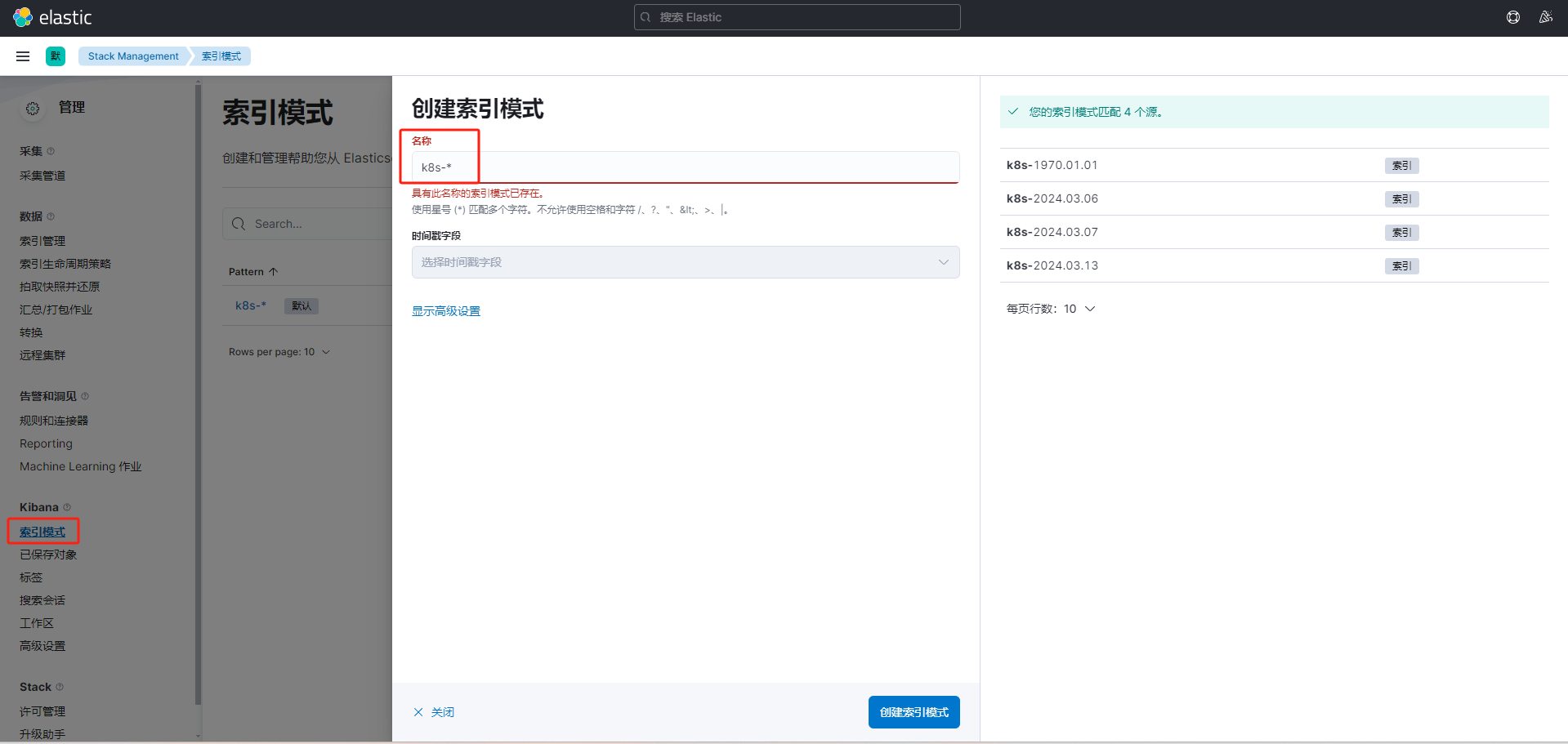
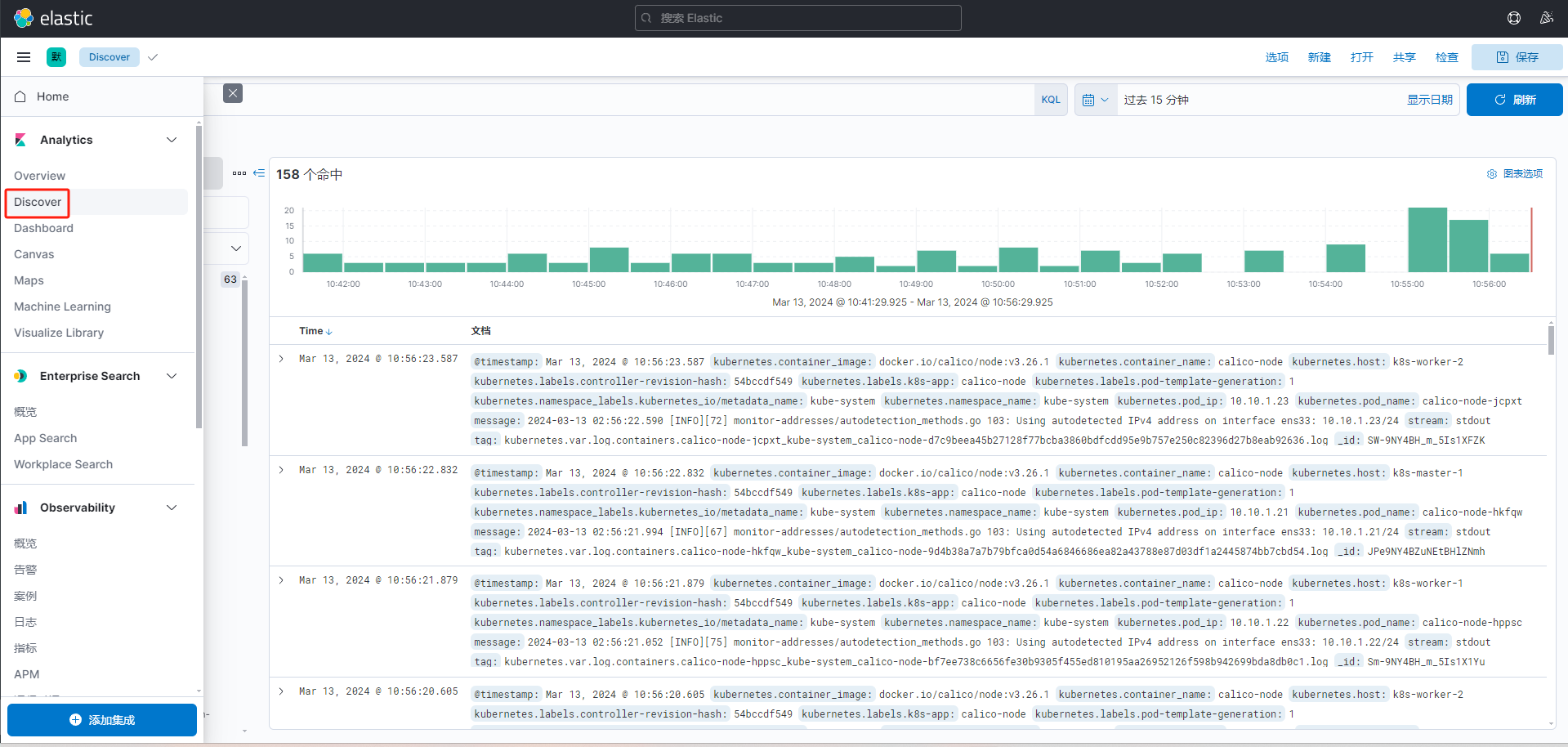
图形界面配置
在上面的配置中,kibana通过nodeport的svc暴露.访问对应端口即可.
ES数据结构
索引(index): 类似数据库的
表(table).它是文档的容器,通常被用来存储相同类型和相关性强的数据.文档(document): 类似数据库的
行(row).存储数据的基本单位,由字段组成.,每个字段都保存数据的一部分.字段(field): 类似数据库的
列(column).类型(type): 7.x+后,只有一个普通的”_doc”类型.
分片(shards): ES中的一个索引可以分割成多个分片.每个分片就是一个独立的搜索引擎.每个分片存储在集群中的不同节点.从而实现容量的水平扩展.
副本(replicas):为了高可用和冗余,es允许你创建
分片的一份或多份复制,这就是副本.副本有两种类型:- 主分片: 一个索引原始的,可写的分片 - 副本分片: 主分片的复制,只读.数据写入时,先写到主分片,然后复制到副本分片
数据查询时,ES会把查询发送到每个相关的分片上,然后把结果组合在一起返回,另外ES可以并行查询主分片和副本分片,也就是ES查询速度快的原因之一.
比如我们用es存储一个购物网站的数据:
首先创建一个
products的索引,用来存储网站上所有产品的信息.旧版本我们可以自定义
类型,用来区分同一索引中不同种类的文档1
2
3
4
5
6
7// 旧版示例
- 索引:products
- 类型:electronics
- 文档:{ "product_id": "E123", "name": "电视机", "brand": "XYZ" }
- 文档:{ "product_id": "E456", "name": "智能手机", "brand": "ABC" }
- 类型:clothing
- 文档:{ "product_id": "C789", "name": "夹克", "brand": "DEF" }1
2
3
4//7.x后删除了类型概念,所有文档被认为属于一个通用的 _doc 类型,我们可以通过其他方式(如使用字段)来区分不同的数据
- 索引:products
- 文档:{ "product_id": "E123", "category": "electronics", "name": "电视机", "brand": "XYZ" }
- 文档:{ "product_id": "C789", "category": "clothing", "name": "夹克", "brand": "DEF" }文档由
字段组成,比如上面的name就是一个字段,Smartphone XYZ Pro就是该字段的值
ES索引阶段
配置es节点时,可以通过配置文件定于哪个节点是热哪个节点是温,然后通过ILM策略来指定存储对应阶段的数据.
1 | |
ES对于索引有热(hot),温(warm),冷(cold)和删除(delete)阶段的定义.针对不同的阶段,ES提供对应的操作和策略配置.
- 热: 用于存储新数据,活跃数据频繁读写
- 温: 用于存储相对没那么频繁使用的数据
- 冷: 用于存储很少访问但仍然需要保留的旧数据
- 删除: 就是删除:)
索引生存周期
Index Life Manager(ILM),分两部分组成:
索引策略
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43# 创建一个名为my_data_lifecycle的策略
curl -X PUT "localhost:9200/_ilm/policy/my_data_lifecycle" -H "Content-Type: application/json" -d'
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms", # 数据一旦进入es即为hot数据
"actions": {
"rollover": { # 索引滚动(见下文解释)
"max_age": "1d",
"max_size": "50GB"
},
"set_priority": { # 在hot阶段设置较高的优先级,以优化该阶段索引的性能
"priority": 100
}
}
},
"warm": {
"min_age": "10d", # 10天后转为暖数据
"actions": {
"allocate": { # 分片分配过滤器中使用这些自定义属性来控制索引分片的分配,warm数据的主数据和分片都只存于有"warm"属性的节点中(hot的配置类似)
"include": {},
"exclude": {},
"require": {
"data": "warm"
}
},
"set_priority": { # 设置相对较低的优先级,系统就不会分配过多的性能到该阶段的索引上
"priority": 50
}
}
},
"delete": {
"min_age": "30d", # 超过30天的数据即删除
"actions": {
"delete": {
"delete_searchable_snapshot": true
}
}
}
}
}
}'索引滚动:
- 当旧索引达到预设的条件,es会自动创建一个新索引,通常以原索引名后加个递增的id来命名
- 配置索引滚动一定要指定
滚动别名,当一个索引被滚动,新索引被创建,别名就从指向旧索引改为指向新索引,只有被别名指向索引才是可写的 - 也就是意味着旧索引会变为只读状态,新索引变为读写状态,数据会持续写入新索引,旧索引则根据ILM策略做处理.
这个功能可以保证系统的查询性能,毕竟一个索引数据量越大,查询自然就会越慢
索引模板
通过模板来应用创建的策略
1
2
3
4
5
6
7
8
9
10
11
12# 创建名为k8s_data_template的索引模板
curl -X PUT "localhost:9200/_index_template/k8s_data_template" -H "Content-Type: application/json" -d'
{
"index_patterns": ["k8s-*"], # 通过patterns匹配索引
"template": {
"settings": {
"number_of_shards": 1, # 配置索引的主分片数,最少要有1个主分片
"index.lifecycle.name": "my_data_lifecycle",
"index.lifecycle.rollover_alias": "k8s" # 指定索引滚动别名
}
}
}'