AIGC-AI绘画

概述
AI绘画是通过模拟图像增加噪点对图像进行分析学习处理后再进行重新组合降噪还原的扩散过程,称为
图像扩散原论文名: High-Resolution lmage Synthesis with Latent Diffusion Models
所以按我理解,AI绘画并不是本质上的从0到1的创造,而是模仿重组.不过模仿重组本身就不是创造了吗?
SD安装
环境
- python
- CUDA驱动
- GIT
原生webui
python<=3.10.6
1
2
3git clone https:/github.com/AUTOMATIC1111/stable-diffusion-webui.git
# 黑色主题
# http://127.0.0.1:7860/?__theme=dark
原生webui分支
在上面的基础上做了些优化,本质功能没有差别
1
2
3git clone https://github.com/vladmandic/automatic
# 启动后不会自动弹出webui要手动访问
# http://127.0.0.1:7860/
大神整合包
- B站: 秋葉aaaki
- B站: 独立研究员-星空ki (支持A卡, A卡选CPU或者自动运行)
- B站: ToniiiX (支持全系列A卡,N卡,M1芯片; 支持mac, windows, linux; 没有自带模型)
插件安装
插件目录: path_to_sd\extensions
直接在插件目录下
git clone {插件地址}通过webui安装
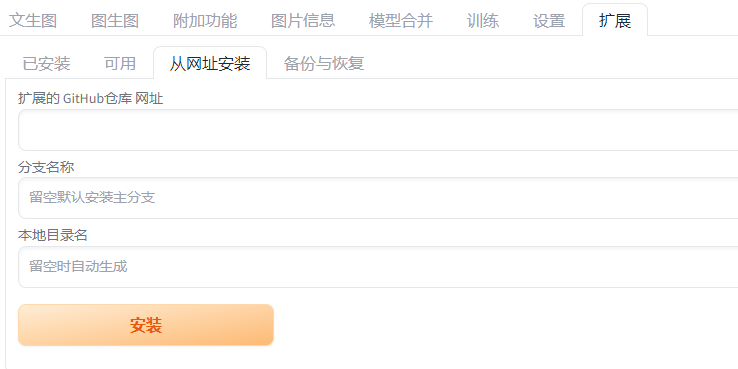
原生webui内置插件:
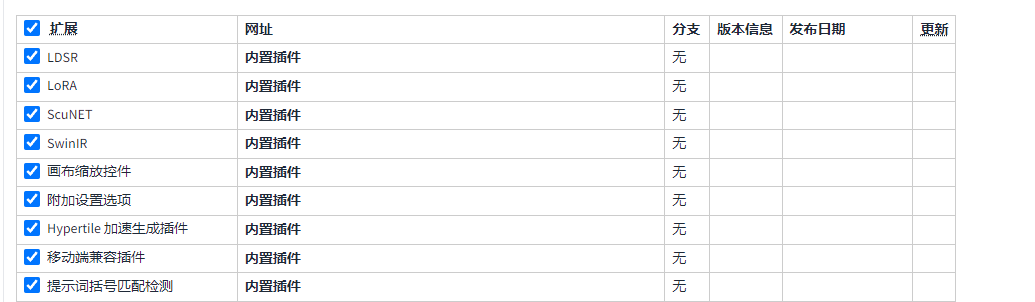
常用插件推荐:
通用参数

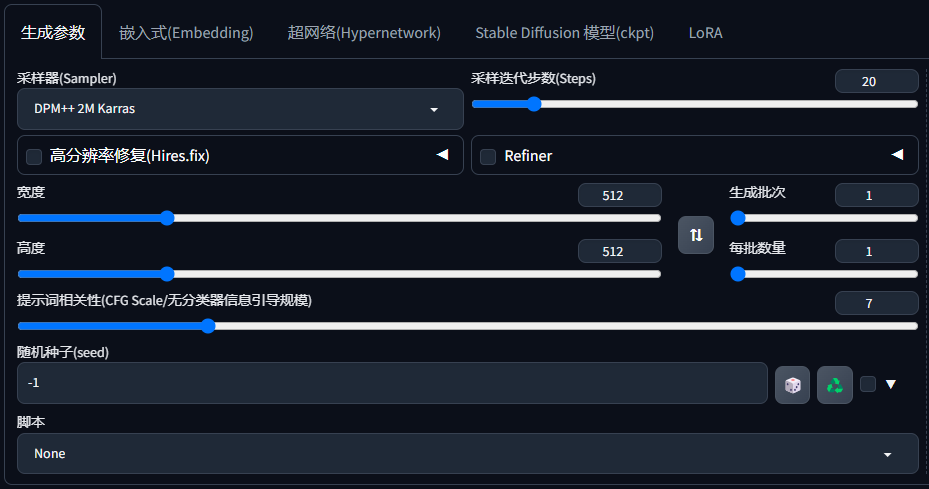
大模型
模型路径: path_to_sd\models\Stable-diffusion
作用: 决定画风

SD模型又叫
ckpt(check point),大模型,主模型或底模型,后缀为.ckpt或.safetensors
模型下载网站:
VAE
变分自编码器,基于深度学习的生成模型
调出配置项: 设置-->用户界面-->快捷设置列表-->sd_vae-->保存设置-->重启webui

vae也有单独的模型, 存放目录: path_to_sd\models\VAE,不过目前很多大模型训练时已经自带VAE
作用: 滤镜与微调,如下左图没有使用VAE

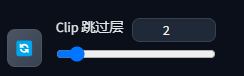
CLIP skip
一种语言理解模型,一共有12个值(0-12),表示理解提示词的模糊程度,层越低,越贴切提示词(越严谨).
一般调到2-4,如果希望sd更自主,可以相应调高

调出配置项: 设置-->用户界面-->快捷设置列表-->CLIP_stop_at_last_layers-->保存设置-->重启webui
采样方法 sampler
不同的采样器影响图片的扩散过程以及色彩.一般模型训练者会提示采用哪种采样器会比较好.

常用的采样器:
- Euler a
- Eular
- DPM2
- DDIM
- DPM++ 2M Karras
迭代步数 steps
就是图像扩散的步数,可以理解为ai绘画的笔数.迭代步数一般要根据使用的采样器决定.并不是步数越高就越精细.
一般情况下可以设置到20-50

提示词相关性 CFG Scale
影响提示词的权重: 不同于提示词语法权重,而是整个图片扩散过程提示词与其他参数占比的总权重
安全值: 7-15

面部修复
新版本sd webui默认打开
可以在设置中关闭
因为人物像中最复杂的就是脸和手,如果分辨率不高,像素太小,AI画出的人物脸部和手部就很容易崩坏.如果调高分辨率也有修复的效果.
但是绝大多数模型在训练的时候都是采用512*512去训练,如果用高分辨率来生成,空的部分AI会随意填充,比如你想画1 girl,它就给你2 girl.
这时候只能生成512*512的图,但是又要高分辨率,此时就可以用到高清修复.
高清修复 Hires. fix
高清修复有各种对图片放大重绘的算法,实际上是图片重绘生成更大更多细节的图片.
平铺
生成的图可以无缝拼合使用(材质图)
随机种子 seed
种子就是噪声,每一个种子表示不同的噪声图.
种子数=1;迭代=1就是原始噪声图.
最大种子数: 18446744073709550591 (超过就会生成失败)
使用上一次的随机种子数: 使用上一次的随机种子,后面生成的图都会参考上一次的图来画.

-1: 不使用特定的随机种子,出图完全随机.
高级功能: 对噪声图重新组合
差异随机种子 和 差异强度:
差异种子与随机种子差值越大,构图影响越大,同时变化幅度由差异强度决定固定参数:
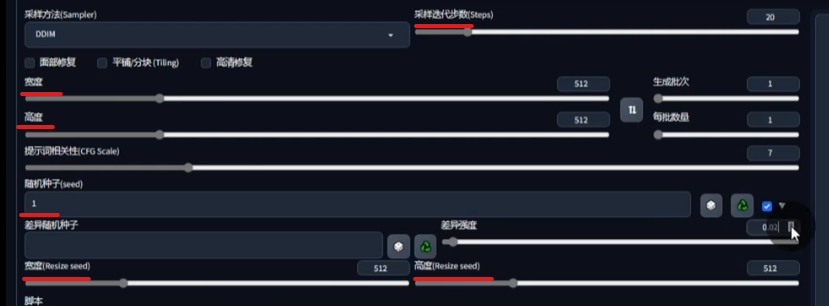
只调节差异种子和差异强度输出如下:

随机种子=差异种子时: 不论差异强度多高,图片都不会变化

- 宽度和高度: 比如设置300*300,差异种子控制的就是差异种子内的噪声,也就是300*300里面的部分

总结: 当我们得到一张基本符合要求的图,但是对细节有其他想法,就可以调差异种子.通过差异种子,可以对噪声图进行局部重绘,从而会图差生细微影响.在不影响整体构图下,细改图片.(其实类似局部重绘)

文生图
text2img原理:
提示词+参数==>代码==>采样器sampler==>采样方法sampling method==>对底模ckpt进行采样==>图像
正向提示词
可以识别:
- 英文:
- 单词: 一个女孩,高挑,站立,地面 (由于sd对于单词理解能力更强,所以
优先使用) - 短句: 一个站立在地面上的高挑女孩
- 单词: 一个女孩,高挑,站立,地面 (由于sd对于单词理解能力更强,所以
- 数字
- 符号
- emoji表情
语序: 画面质量–>主要元素–>细节
- 画面质量/概念:
- 图像质量: 高细节, 高分辨率, 超写实主义, HD, 8k, 16K等
- 风格: 卡通, 贴纸, 漫画, 印象, 肖像, 像素, 新海城, 赛博朋克等
- 构图: 中心, 水平, 随直, 三分法, 对称法, 对角线, 框架, 重复构图等
- 灯关: 工作室, 电影照明, 美丽的灯光, 柔光, 逆光, 人物发光, 测光, 云隙光等
- 主要元素/主体:
- 人物: 武士, 护士, 魔法师, 美少女战士, 男人, 女人, 女孩, 男孩, 兔女郎, 特定人物等
- 动物: 猴子, 鸡, 狗, 兔, 十二生肖, 怪兽, 鱼, 老鼠, 鸟, 鸭, 鹅等
- 事物: 瓶子, 伞, 武器, 背包, 墨镜, 手机, 电脑, 工具等
- 风景: 天空, 森林, 海洋, 山, 水, 花, 道路桥梁等
- 姿态: 站立, 坐, 行走, 奔跑, 跳跃, 半蹲, 抬头, 回身, 侧卧, 手放身后, 二郎腿等
- 服装: 短袖, 长衫, 连衣裙, 长袍, 短裤, 丝袜, 手套, 吊带, 牛仔裤, 围巾, 高跟鞋等
- 道具: 帽子, 眼镜, 武器, 手链, 项链, 耳坠, 耳环等
- 细节:
- 场景: 室内, 室外, 客厅, 餐厅, 咖啡店, 酒吧, 幻想场景等
- 环境: 晴天, 雨天, 阴天, 春夏秋冬, 白天, 傍晚, 夜晚等
- 细小元素: 表情, 妆容, 发髻, 雷, 电, 水, 火等不影响整体构图的元素
- 其他
符号
分隔符: 权重排序, 分隔符前权重高, 分隔符后权重低.一般情况下都使用,和换行.

权重符号
(提示词): 括号内提示词权重* 1.1
{提示词}: 括号内提示词权重* 1.05
[提示词]: 括号内提示词权重* 0.9
(提示词:1.2): 自定义权重
可以叠加使用:

实际使用:
当我们希望某个元素在图片中出现更多,就可以调高权重,但是权重超过1.5图片同意崩,所以一般不要超过1.5
连接符号
+和_: 并列前后提示词的权重
提示词1|提示词2: 循环竖线前后提示词的影响扩散效果(迭代步数1,3,5…提示词1生效; 迭代步数2,4,6…提示词2生效)
AND: 前后需要加上空格, 对前后提示词产生融合效果

分布扩散符号
[提示词:步数]: 指定步数开始生效
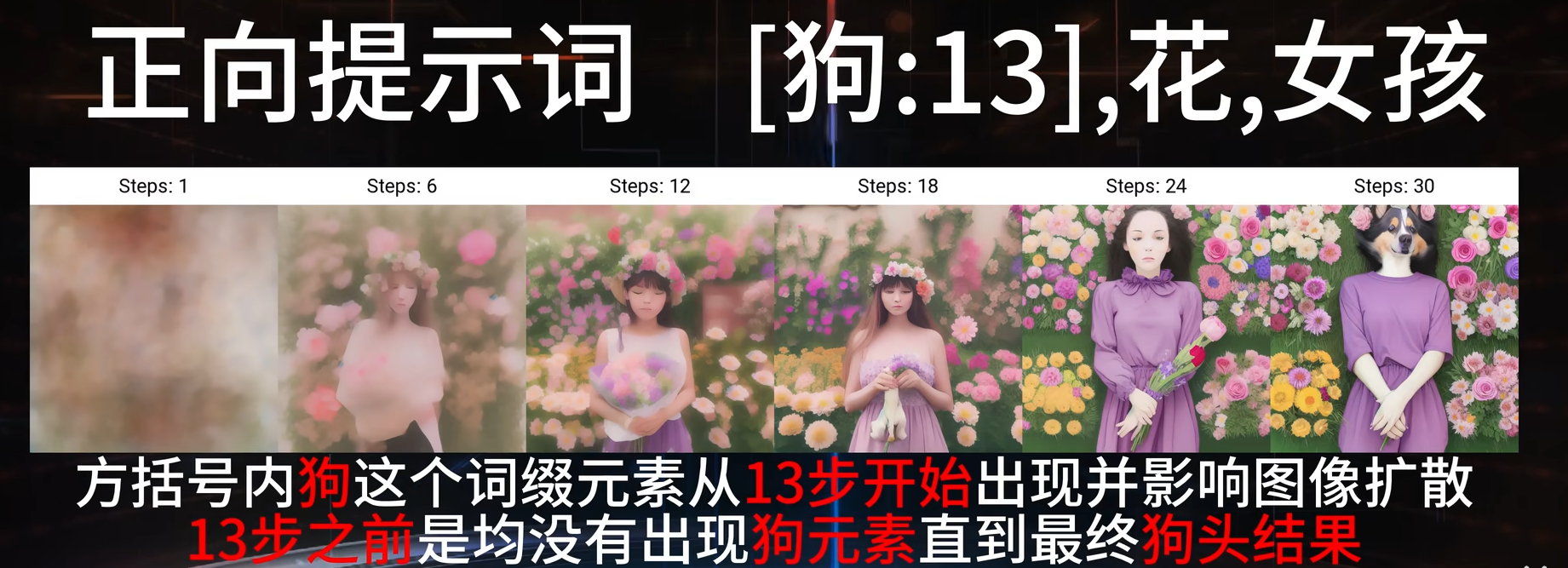
[提示词::步数]:指定步数停止生效

[提示词1:提示词2:步数]:可以同时控制两个提示词, 指定步数前提示词1生效, 指定步数后提示词2生效

[提示词1|提示词2]: 循环影响

示例:

反向提示词
通用模板保存即可(正向亦可保存).
模板保存目录: path_to_sd\styles.csv,用记事本打开,删除要删除的内容保存即可,不能用excel打开,否则会报错
图生图
img2img: 通过提供的图像产生一个新图像
原理:
SD将输入的源图(step1)隐藏再随机种子的噪点图后(step2),基于这个原始噪声图再扩散.所以源图的颜色构图等总会在后面的迭代中出现.
所以SD不是理解了源图,而是通过源图也随机种子组合
原始噪声图再加上提示词和参数结合底模,找到最匹配的元素扩散出结果


重绘幅度
表示添加到输出图像的噪声量,幅度值越大,图像变化越多

局部重绘
通过手涂蒙版工具对源图.结合提示词和参数,进行局部的图生图处理.
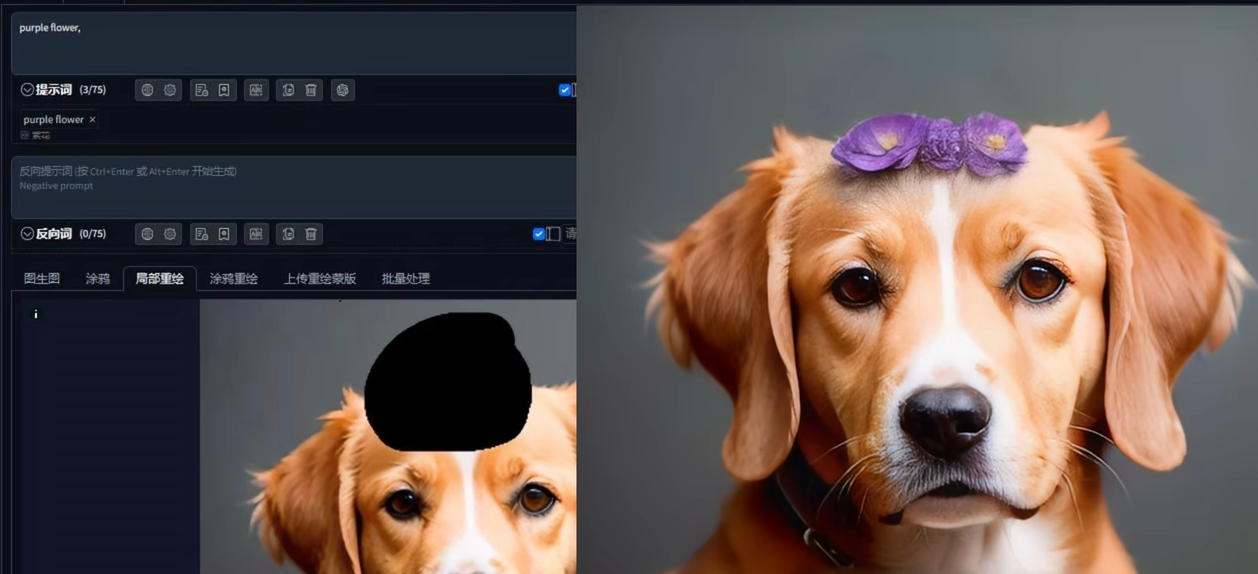
模板边缘模糊度: 重绘边缘羽化功能,使局部生成部分看上去与源图更贴合.但是SD本身不会理解局部重绘部分与原图的关系,要想真正切合,需要使用插件.

涂鸦
对原图上色重绘,同样可以根据提示词引导噪声图.

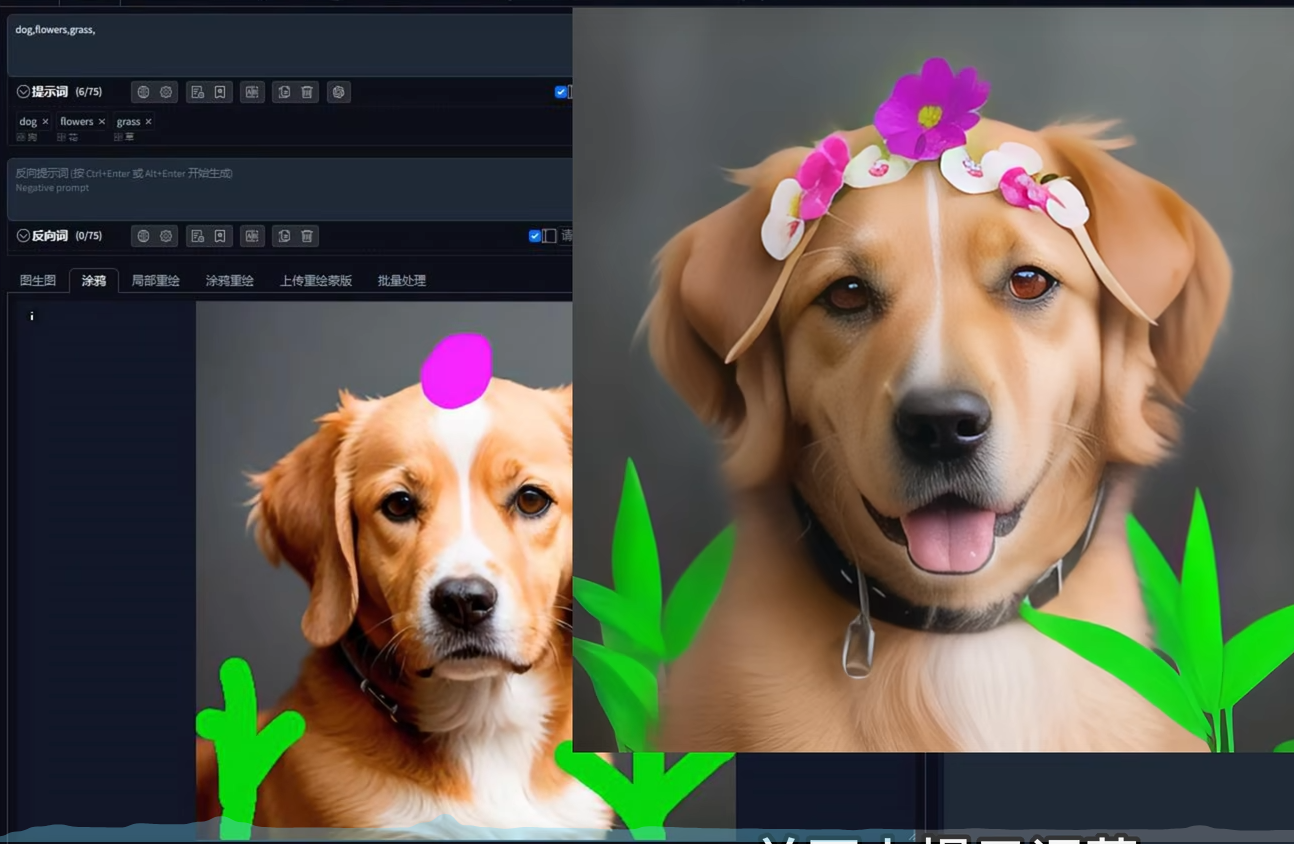
涂鸦重绘
涂鸦+重绘, 在不改变原图的基础下,对原图进行涂鸦输入,也可以通过调整蒙版透明度改颜色.
上传蒙版
通过其他工具生成更加匹配的蒙版,更加精确地控制重绘的区域.(白色才是蒙版区域)
批量重绘
通过预设,批量使用重绘功能.电商必备
需要提前准备好:
- 原图目录
- 蒙版目录
- 输出目录
- controlNet插件图像目录

缩放模式
文生图第一步是预处理噪声图
图生图第一步是预处理原图

潜空间: 预处理时噪声图(图生图中原图在随机噪声后融合后产生的原始噪声图)背后的空间.
仅调整大小(潜空间放大): 进入潜空间前先调整大小再预处理,进入潜空间后再静态放大.所以潜空间放大的原图会出现模糊.

重绘参考内容

填充: 对重绘区域的原图进行高度模糊处理,只保留原图色度,再隐藏到随机噪声图后面.原图颜色+随机噪声图(保留原图颜色,不保留原图结构)

原图: 不改变原图的预处理方式,之间将原图隐藏在随机噪声图后.原图颜色结构+随机噪声图
潜空间噪声: 在重回区域填充潜空间内容(也是一张噪声图),然后再预处理叠加随机噪声图,也就是双层噪声图
空白潜空间: 不使用潜空间的内容,直接在重绘区域填充噪声图.单层噪声图
重绘区域

整张重绘/以原图尺寸重绘: 对整张图片使用预处理方式,扩散局部内容

仅模板区域: 只对重绘区域进行预处理

以蒙版尺寸重绘时的外部填充半径(像素):
控制填入噪点的像素大小,值越低,重绘部分像素越多.